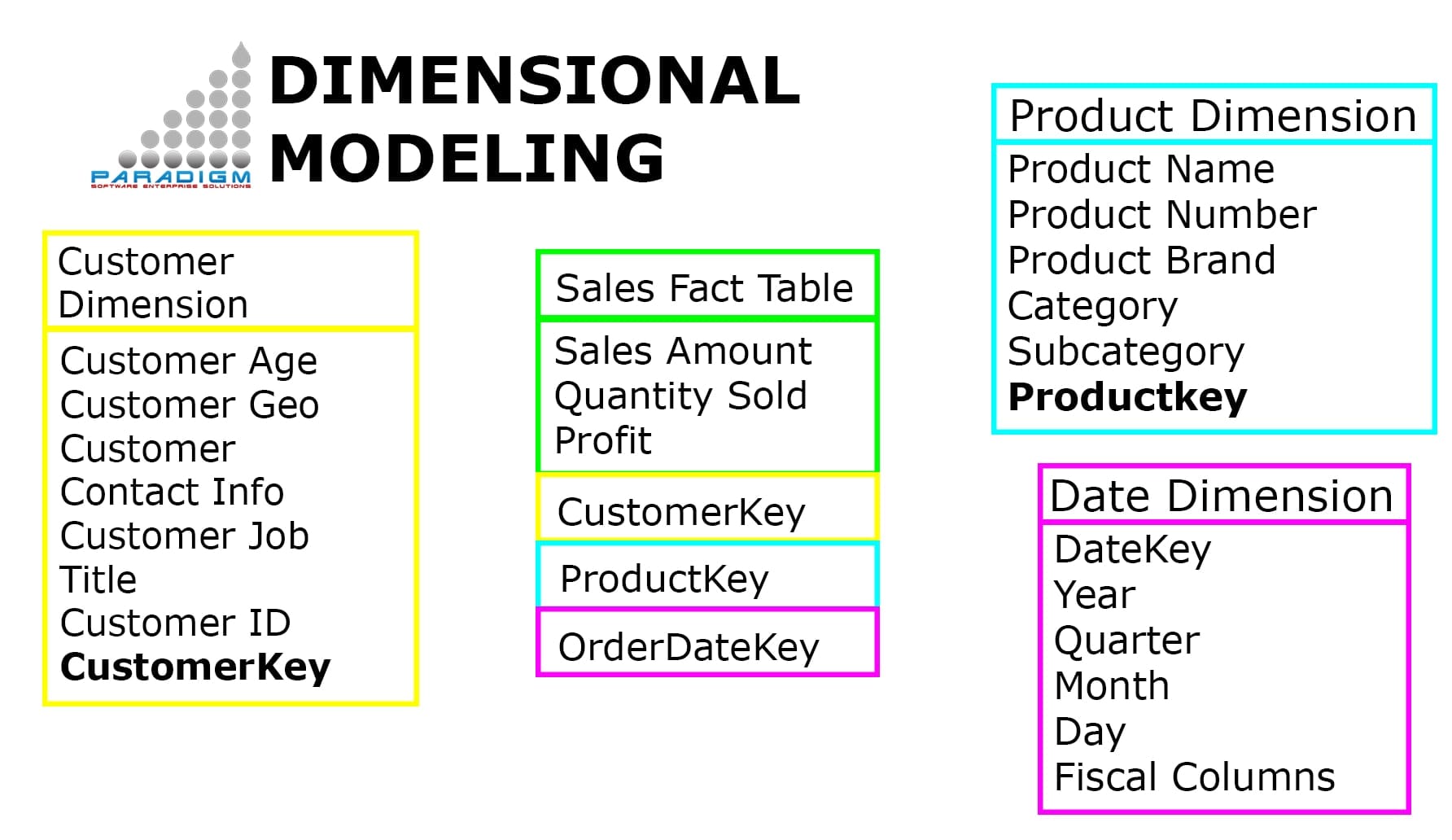
Dimensional Keys
If the facts are truly measures taken repeatedly, you find that fact tables always create a characteristic many-to-many relationship among the dimensions. Many customers buy many products in many stores at many times.
Therefore, you logically model measurements as fact tables with multiple foreign keys referring to the contextual entities. And the contextual entities are each dimensions with a single primary key. Although you can separate the logical design from the physical design, in a relational database fact tables and dimension tables are most often explicit tables.
- At the higher level, tables are explicitly declared together with their fields and keys.
- The lower level of physical design describes the way the bits are organized on the disk and in memory. Not only is this design highly dependent on the particular database, but some implementations may even “invert” the database beneath the level of table declarations and store the bits in ways that are not directly related to the higher-level physical records. What follows is a discussion of the higher level only.
A fact table in a pure star schema consists of multiple foreign keys, each paired with a primary key in a dimension, together with the facts containing the measurements. The foreign keys in the fact table are labeled FK, and the primary keys in the dimension tables are labeled PK. (The field labeled DD, special degenerate dimension key, is discussed later in this column.)
- The lower level of physical design describes the way the bits are organized on the disk and in memory. Not only is this design highly dependent on the particular database, but some implementations may even “invert” the database beneath the level of table declarations and store the bits in ways that are not directly related to the higher-level physical records. What follows is a discussion of the higher level only.
Foreign keys in the fact table obey referential integrity with respect to the primary keys in their respective dimensions. In other words, every foreign key in the fact table has a match to a unique primary key in the respective dimension. Note that this design allows the dimension table to possess primary keys that aren’t found in the fact table. Therefore, a product dimension table might be paired with a sales fact table in which some of the products are never sold. This situation is perfectly consistent with referential integrity and proper dimensional modeling.
In the real world, there are many compelling reasons to build the FK-PK pairs as surrogate keys that are just sequentially assigned integers. It’s a major mistake to build data warehouse keys out of the natural keys that come from the underlying data sources.
Occasionally a perfectly legitimate measurement will involve a missing dimension. Perhaps in some situations a product can be sold to a customer in a transaction without a store defined. In this case, rather than attempting to store a null value in the Store FK, you build a special record in the Store dimension representing “No Store.” Now the No Store condition has a perfectly normal FK-PK representation in the fact table.
Logically, a fact table doesn’t need a primary key because, depending on the information available, two different legitimate observations could be represented identically. Practically speaking, this is a terrible idea because normal SQL makes it very hard to select one of the records without selecting the other. It would also be hard to check data quality if multiple records were indistinguishable from each other.